Introduction¶
MCMC Software¶
Markov chain Monte Carlo (MCMC) methods are a class of algorithms for simulating autocorrelated draws from probability distributions [12][27][38][77]. They are widely used to obtain empirical estimates for and make inference on multidimensional distributions that often arise in Bayesian statistical modelling, computational physics, and computational biology. Because MCMC provides estimates of distributions of interest, and is not limited to point estimates and asymptotic standard errors, it facilitates wide ranges of inferences and provides for more realistic prediction errors. An MCMC algorithm can be devised for any probability model. Implementations of algorithms are computational in nature, with the resources needed to execute algorithms directly related to the dimensionality of their associated problems. Rapid increases in computing power and emergence of MCMC software have enabled models of increasing complexity to be fit. For all its advantages, MCMC is regarded as one of the most important developments and powerful tools in modern statistical computing.
Several software programs provide Bayesian modelling via MCMC. Programs range from those designed for general model fitting to those for specific models. WinBUGS, its open-source incarnation OpenBUGS, and the ‘BUGS’ clone Just Another Gibbs Sampler (JAGS) are among the most widely used programs for general model fitting [56][70]. These three provide similar programming syntaxes with which users can specify statistical models by simply stating relationships between data, parameters, and statistical distributions. Once a model is specified, the programs automatically formulate an MCMC sampling scheme to simulate parameter values from their posterior distribution. All aforementioned tasks can be accomplished with minimal programming and without specific knowledge of MCMC methodology. Users who are adept at both and so inclined can write software modules to add new distributions and samplers to OpenBUGS and JAGS [93][95]. General model fitting is also available with the MCMC procedure found in the SAS/STAT ® software [48]. Stan is a newer and similar-in-scope program worth noting for its accessible syntax and automatically tuned Hamiltonian Monte Carlo sampling scheme [98]. PyMC is a Python-based program that allows all modelling tasks to be accomplished in its native language, and gives users more hands-on access to model and sampling scheme specifications [69]. Programs like GRIMS [65] and LaplacesDemon [99] represent another class of programs that fit general models. In their approaches, users work with the functional forms of (unnormalized) probability densities directly, rather a domain specific modelling language (DSL), for model specification. Examples of programs for specific models can be found in the R catalogue of packages. For instance, the arm package provides Bayesian inference for generalized linear, ordered logistic or probit, and mixed-effects regression models [33], MCMCpack fits a wide range of models commonly encountered in the social and behavioral sciences [59], and many others that are more focused on specific classes of models can be found in the “Bayesian Inference” task view on the Comprehensive R Archive Network [68].
The Mamba Package¶
Mamba [87] is a julia [4] package designed for general Bayesian model fitting via MCMC. Like OpenBUGS and JAGS, it supports a wide range of model and distributional specifications, and provides a syntax for model specification. Unlike those two, and like PyMC, Mamba provides a unified environment in which all interactions with the software are made through a single, interpreted language. Any julia operator, function, type, or package can be used for model specification; and custom distributions and samplers can be written in julia to extend the package. Conversely, interactions with and extensions to OpenBUGS and JAGS can involve three different programming environments — R wrappers used to call the programs, their DSLs, and the underlying implementations in Component Pascal and C++. Advantages of a unified environment include more flexible model specification; tighter integration with supplied functions for convergence diagnostics and posterior inference; and faster development, testing, and debugging of extensions. Advantages of the BUGS DSLs include more concise model specification and facilitation of automated sampling scheme formulation. Indeed, sampling schemes must be selected manually in the initial release of Mamba. Nevertheless, Mamba holds other distinct advantages over existing offerings. In particular, it provides arbitrary blocking of model parameters and designation of block-specific samplers; samplers that can be used with the included simulation engine or apart from it; and command-line access to all package functionality, including its simulation API. Likewise, advantages of the julia language include its familiar syntax, focus on technical computing, and benchmarks showing it to be one or more orders of magnitude faster than R and Python [3]. Finally, the intended audience for Mamba includes individuals interested in programming in julia; who wish to have low-level access to model design and implementation; and, in some cases, are able to derive full conditional distributions of model parameters (up to normalizing constants).
Mamba allows for the implementation of an MCMC sampling scheme to simulate draws for a set of Bayesian model parameters  from their joint posterior distribution. The package supports the general Gibbs [29][34] scheme outlined in the algorithm below. In its implementation with the package, the user may specify blocks
from their joint posterior distribution. The package supports the general Gibbs [29][34] scheme outlined in the algorithm below. In its implementation with the package, the user may specify blocks 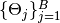 of parameters and corresponding functions
of parameters and corresponding functions 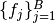 to sample each
to sample each 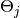 from its full conditional distribution
from its full conditional distribution 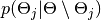 . Simulation performance (efficiency and runtime) can be affected greatly by the choice of blocking scheme and sampling functions. For some models, an optimal choice may not be obvious, and different choices may need to be tried to find one that gives a desired level of performance. This can be a time-consuming process. The Mamba package provides a set of julia types and method functions to facilitate the specification of different schemes and functions. Supported sampling functions include those provided by the package, user-defined functions, and functions from other packages; thus providing great flexibility with respect to sampling methods. Furthermore, a sampling engine is provided to save the user from having to implement tasks common to all MCMC simulators. Therefore, time and energy can be focused on implementation aspects that most directly affect performance.
. Simulation performance (efficiency and runtime) can be affected greatly by the choice of blocking scheme and sampling functions. For some models, an optimal choice may not be obvious, and different choices may need to be tried to find one that gives a desired level of performance. This can be a time-consuming process. The Mamba package provides a set of julia types and method functions to facilitate the specification of different schemes and functions. Supported sampling functions include those provided by the package, user-defined functions, and functions from other packages; thus providing great flexibility with respect to sampling methods. Furthermore, a sampling engine is provided to save the user from having to implement tasks common to all MCMC simulators. Therefore, time and energy can be focused on implementation aspects that most directly affect performance.

Mamba Gibbs sampling scheme
A summary of the steps involved in using the package to perform MCMC simulation for a Bayesian model is given below.
Decide on names to use for julia objects that will represent the model data structures and parameters (
). For instance, the Tutorial section describes a linear regression example in which predictor
and response
are represented by objects
xandy, and regression parameters,
, and
by objects
b0,b1, ands2.Create a dictionary to store all structures considered to be fixed in the simulation; e.g., the
linedictionary in the regression example.Specify the model using the constructors described in the MCMC Types section, to create the following:
- A
Stochasticobject for each model term that has a distributional specification. This includes parameters and data, such as the regression parametersb0,b1, ands2that have prior distributions andythat has a likelihood specification.- A vector of
Samplerobjects containing supplied, user-defined, or external functions- A
Modelobject from the resulting stochastic nodes and sampler vector.Simulate parameter values with the
mcmc()function.Use the MCMC output to check convergence and perform posterior inference.